7 minutes
Cassandra : Overview, how is data written and read?
- [Characterstics] (#h2-characterstics-h2)
- [How does it internally work] (#h2-how-does-it-internally-work-h2)
- [References] (#h2-references-h2)
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra’s support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
Characterstics
Fault tolerant Data is automatically replicated to multiple nodes for fault-tolerance. Replication across multiple data centers is supported. Failed nodes can be replaced with no downtime.
Performant Cassandra consistently outperforms popular NoSQL alternatives in benchmarks and real applications, primarily because of fundamental architectural choices.
Decentralized There are no single points of failure. There are no network bottlenecks. Every node in the cluster is identical.
Scalable Some of the largest production deployments include Apple’s, with over 75,000 nodes storing over 10 PB of data, Netflix (2,500 nodes, 420 TB, over 1 trillion requests per day), Chinese search engine Easou (270 nodes, 300 TB, over 800 million requests per day), and eBay (over 100 nodes, 250 TB).
Durable Cassandra is suitable for applications that can’t afford to lose data, even when an entire data center goes down.
You’re in control Choose between synchronous or asynchronous replication for each update. Highly available asynchronous operations are optimized with features like Hinted Handoff and Read Repair.
Elastic Read and write throughput both increase linearly as new machines are added, with no downtime or interruption to applications.
Professionally Supported Cassandra support contracts and services are available from third parties.
How does it internally work
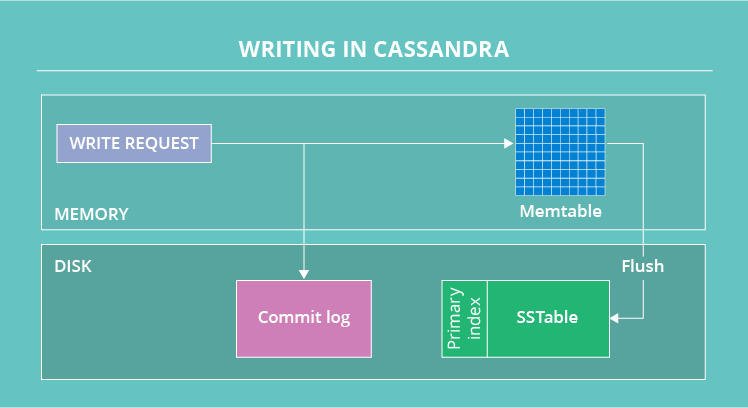
Entire write happens in following steps
- Logging data in the commit log
- Writing data to the memtable
- Flushing data from the memtable
- Storing data on disk in SSTables
- Compaction
First thing it does, is writing the data in commit log, which is on disc, because of that it is durable. It is append only log which is sequencial write and that is the reason that write in Cassandra is super fast.
Then it writes data in memtable. The memtable is a write-back cache of data partitions that Cassandra looks up by key. The more a table is used, the larger its memtable needs to be. Cassandra can dynamically allocate the right amount of memory for the memtable or you can manage the amount of memory being utilized yourself.
Row in memtable can have 2 billion columns. After writing data in the column it sends acknowldgement back to client.
The memtable, unlike a write-through cache, stores writes until reaching a limit, and then is flushed. When memtable contents exceed a configurable threshold, the memtable data, which includes indexes, is put in a queue to be flushed to disk. To flush the data, Cassandra sorts memtables by partition key and then writes the data to disk sequentially. The process is extremely fast because it involves only a commitlog append and the sequential write.
SSTables are immutable, not written to again after the memtable is flushed. Consequently, a partition is typically stored across multiple SSTable files So, if a row is not in memtable, a read of the row needs look-up in all the SSTable files. This is why read in Cassandra is much slower than write.
Data in the commit log is purged after its corresponding data in the memtable is flushed to the SSTable. The commit log is for recovering the data in memtable in the event of a hardware failure.
as we know that data for a row in SSTable is not in just one SSTable. Whenever data in a row is updated Cassandra writes a new timestamped version of the inserted or updated data in another SSTable. Cassandra also does not delete in place because the SSTable is immutable. Instead, Cassandra marks data to be deleted using a tombstone. Tombstones exist for a configured time period defined by the gc_grace_seconds value set on the table. During compaction, there is a temporary spike in disk space usage and disk I/O because the old and new SSTables co-exist. This diagram depicts the compaction process:
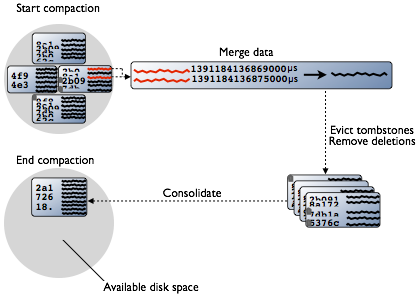
Compaction merges the data in each SSTable data by partition key, selecting the latest data for storage based on its timestamp. Cassandra can merge the data performantly, without random IO, because rows are sorted by partition key within each SSTable. After evicting tombstones and removing deleted data, columns, and rows, the compaction process consolidates SSTables into a single file. The old SSTable files are deleted as soon as any pending reads finish using the files. Disk space occupied by old SSTables becomes available for reuse.
Data input to SSTables is sorted to prevent random I/O during SSTable consolidation. After compaction, Cassandra uses the new consolidated SSTable instead of multiple old SSTables, fulfilling read requests more efficiently than before compaction. The old SSTable files are deleted as soon as any pending reads finish using the files. Disk space occupied by old SSTables becomes available for reuse.
Although no random I/O occurs, compaction can still be a fairly heavyweight operation. During compaction, there is a temporary spike in disk space usage and disk I/O because the old and new SSTables co-exist. To minimize deteriorating read speed, compaction runs in the background.
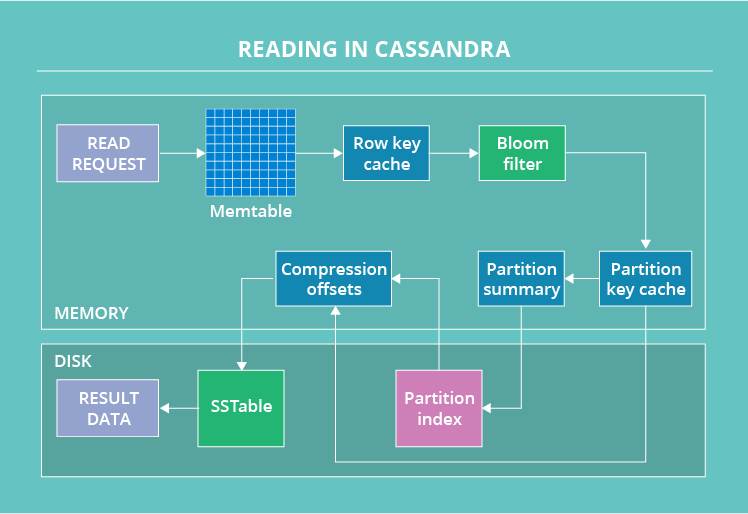
Application client can send data request to any node of your cluster. That node then becomes coordinator for that request. Now it is coordinator’s job to talk to other nodes, get the data and return it to client. When a read request starts its journey, the data’s partition key is used to find what nodes have the data. After that, the request is sent to a number of nodes set by the tunable consistency level for reads. Then, on each node, in a certain order, Cassandra checks different places that can have the data.
- The first one is the memtable.
- If the data is not there, it checks the row key cache (if enabled),
- then the bloom filter and
- then the partition key cache (also if enabled).
- If the partition key cache has the needed partition key, Cassandra goes straight to the compression offsets,
- and after that it finally fetches the needed data out of a certain SSTable.
- If the partition key wasn’t found in partition key cache, Cassandra checks the partition summary
- and then the primary index before going to the compression offsets and extracting the data from the SSTable.
After the data with the latest timestamp is located, it is fetched to the coordinator. Here, another stage of the read occurs. As we’ve stated here, Cassandra has issues with data consistency. The thing is that you write many data replicas and you may read their old versions instead of the newer ones. But Cassandra doesn’t ignore these consistency-related problems: it tries to solve them with a read repair process. The nodes that are involved in the read return results. Then, Cassandra compares these results based on the “last write wins” policy. Hence, the new data version is the main candidate to be returned to the user, while the older versions are rewritten to their nodes. But that’s not all. In the background, Cassandra checks the rest of the nodes that have the requested data (because the replication factor is often bigger than consistency level). When these nodes return results, the DB also compares them and the older ones get rewritten. Only after this, the user actually gets the result.
You run Cassandra in a cluster with more than one nodes. Which not only gives reliability in case any node goes down but this reliability comes with the fact that data of each node is replicated on other nodes. That is why if any node goes down, other nodes start serving that data.
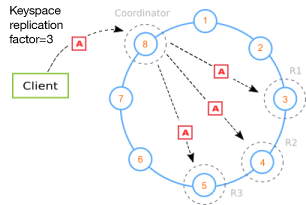
- Client writes local
- Data syncs across WAN
- Replication factor per data center